Kafka分布式设计要点 2018-09-25 21:26:12 最近过了遍Kafka的文档,发现其设计思想和HDFS非常类似,对Kafka的整体设计上也有了更好的理解。 1. 通过topic对数据进行逻辑划分,类似HDFS的一个文件 2. topic的数据分布取决于partition和replica设置,partition数量影响消费者任务的并行度,replica影响的是容错性。 3. partition类似HDFS的split概念,如果一个topic设置多个partition,那么写过来的数据会被拆分写到多个partition中,默认采用round-robin的方式写到不同的partition中,当然可以自定义写入策略。 4. 对于设置多个partition的topic,数据在单个partition内有序,消费数据时,无法保证全局有序,如果需要全局有序,要将partition数量设置为1. 5. 可以控制partition的replica数量,replica也是对标HDFS文件副本的概念,如果一个partition设置了多个replica,那么其中的一个是leader,可以进行数据读写操作,其他的replica节点是follow状态只复制数据,当一个leader节点出问题时,Kafka可以自动切换follow的replica节点为leader节点。 6. Kafka为consumer引入了consumer group的概念,相同的consumer group可以包含多个consumer示例,处理topic数据时,每个consumer处理topic的部分partition数据,因此consumer group的设计可以提高数据处理的并行度,能够实现分布式消费数据的效果。说的有些啰嗦,还是官方文档给的一个图看起来比较贴切: 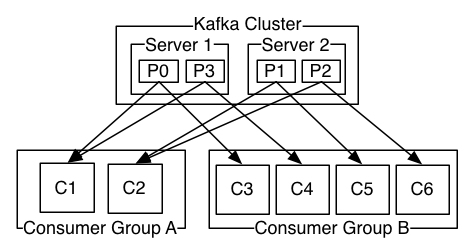 https://mmbiz.qpic.cn/mmbiz/yNKv1P4Q9eUdpbcDU4LclwZOGWlNWkBLNHzh6acDCFnEiblF676zaaLCDickSczRq2ibU8rAa5CzyBFBl7bawia5qw/640?wx_fmt=other&wxfrom=5&wx_lazy=1&wx_co=1 管理监控方案: kafka-eagle、CMAK 非特殊说明,均为原创,原创文章,未经允许谢绝转载。 原始链接:Kafka分布式设计要点 赏 Prev Flutter国际化设置在iOS设备上不生效的问题 Next HDFS双NameNode发生故障后HA无法切换的问题

