sbt结合IDEA对Spark进行断点调试开发 2017-05-15 00:17:42 > 原创文章,谢绝转载 笔者出于工作及学习的目的,经常与Spark源码打交道,也难免对Spark源码做修改及测试。本人一向讲究借助工具提升效率,开发Spark过程中也在摸索如何更加顺畅的对源码进行调试。 Spark基于Scala,采用IntelliJ IDEA和sbt应对日常开发,自然是最佳选择了。如何导入及编译Spark项目,网上资料很多,官网给的教程也比较详细: - <http://spark.apache.org/docs/latest/building-spark.html> - <http://spark.apache.org/developer-tools.html> 本文基于Spark2.x的源码,重点介绍如何使用sbt结合IDEA对Spark进行断点调试开发,这对于经常修改或学习Spark源码的读者较为有益。废话到此,我们进入正题。 ## Spark源码编译 首次拿到Spark源码,直接导入IDEA会有很多错误,因为SQL项目的catalyst中的SQL语法解析依赖ANTLR语法定义,需要通过编译生成代码,如下是采用sbt打包编译的流程: ``` git clone https://github.com/apache/spark.git cd spark build/sbt package ``` ...经过漫长等待,成功编译后,导入IDEA就可以正常看源码了。 > 大家可以采用阿里云的Maven仓库,加速下包的过程,可以参考我的这篇文章:<https://zhuanlan.zhihu.com/p/25279570> ## 编写测试用例 我习惯于直接在Spark项目中写TestCase的方式作为执行Spark的入口,这种方式对于经常修改Spark源码的开发场景很适用,相比在SparkShell中写测试代码有以下好处: - 代码保留在文件中,方便修改重新执行 - 代码在同一个项目中,源码修改后IDEA无需对代码进行二次索引 - 方便进行持续测试(Continuous Test) Spark源码自带大量的TestCase可供我们学习参考,我们以Spark的SQL项目为例,将`spark/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala`复制为`SimpleSuite.scala`。 > 注意,这里不要是使用IDEA自带的复制功能,因为IDEA在复制的时候会重新组织代码中import的次序,这有可能会导致编译出错。正确的姿势应该是: 1. 在IDEA中,找到要复制的文件,右击,复制代码路径 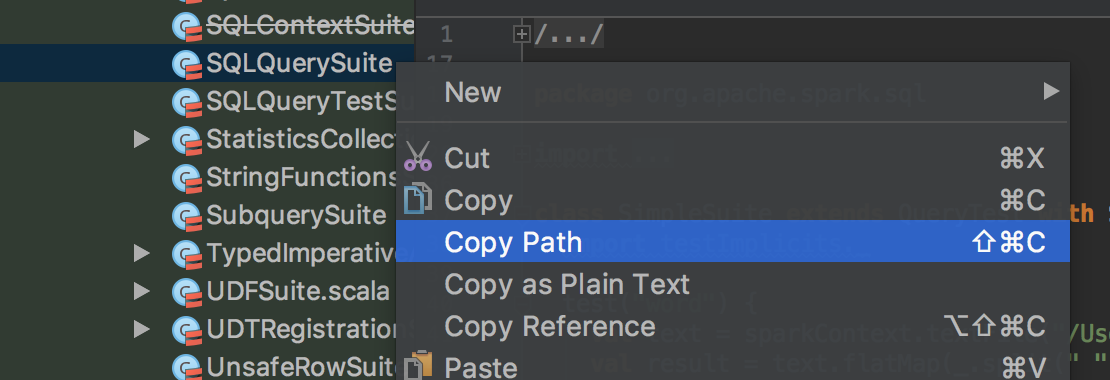 2. 在IDEA的Terminal窗口中执行`cp xxx xxx2`完成复制 我们之所以要基于`SQLQuerySuite`复制出一个`SimpleSuite`文件是因为:Spark为了确保代码风格一致规范(比如每个代码文件头部需要定义Apache的License注释;import的顺序为java,scala,3rdParty,spark),在项目引入了[Scala-style checker](http://www.scalastyle.org/),如果代码不合规范,执行编译会出错。直接复制一个文件在上面做修改可以避免踩到代码风格检查的坑。我将SimpleSuite的内容修改如下: 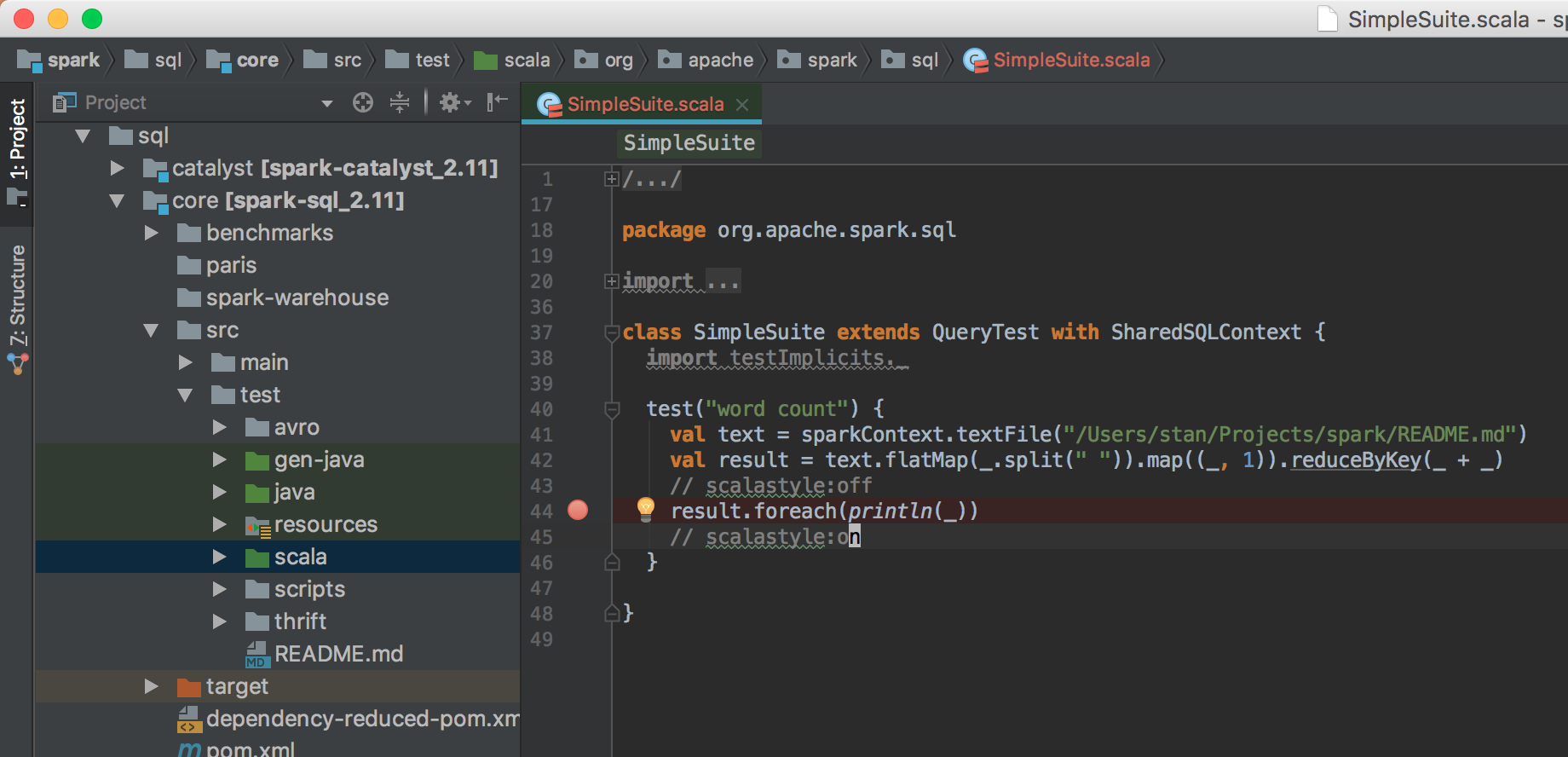 打开IDEA的Terminal窗口,执行build/sbt进入sbt的交互式环境,通过以下方式执行我们的SimpleSuite: ``` > project sql > testOnly *SimpleSuite ``` `project sql`指的是切换到SQL项目,这样在执行testOnly时可以快速定位到我们的SimpleSuite类,可以执行`projects`查看Spark定义的所有子模块,当前所在的模块名称前会有个`*`的标识。首次执行测试的时间比较长,再次执行就会比较快了,如果测试通过的话,会看到如下信息: 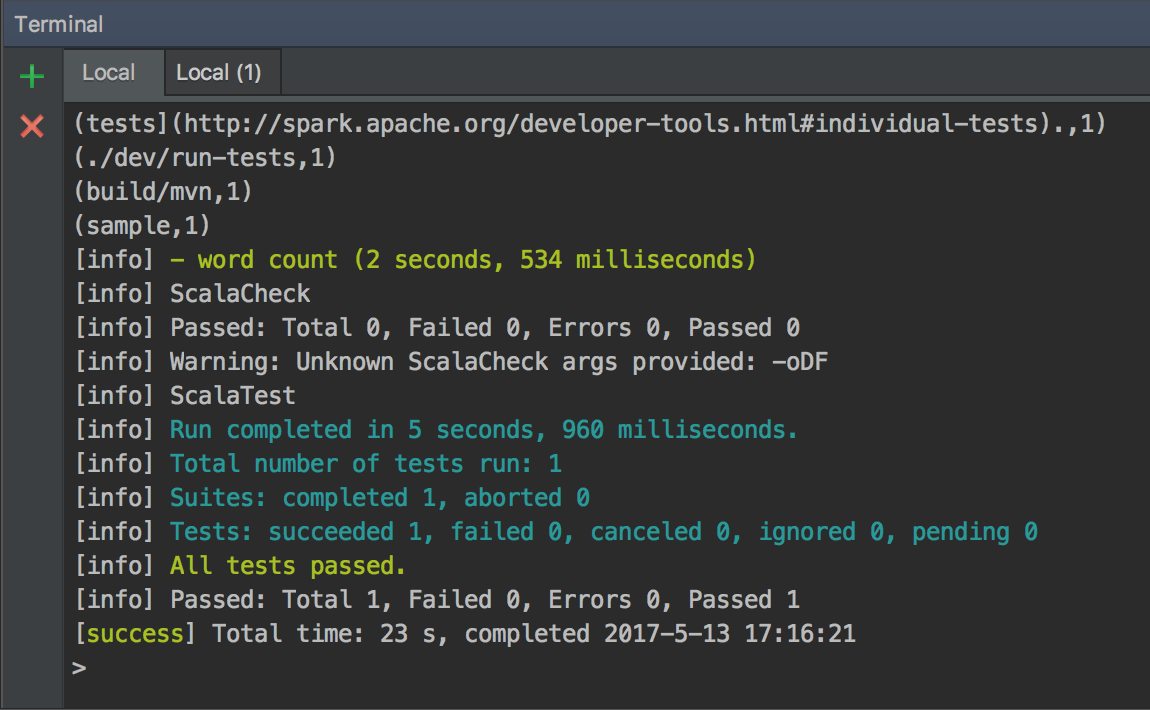 在sbt中执行`exit`退出交互式环境,接下来介绍如何使用sbt结合IDEA进行断点调试。 ## sbt结合IDEA对Spark进行断点调试 由于sbt是在Terminal中单独启动的进程,要对sbt调试,就需要采用IDEA的远程调试功能了。在IDAE的菜单中选择`Run -> Edit Configrations...`,在接下来的窗口中添加一个Remote配置: 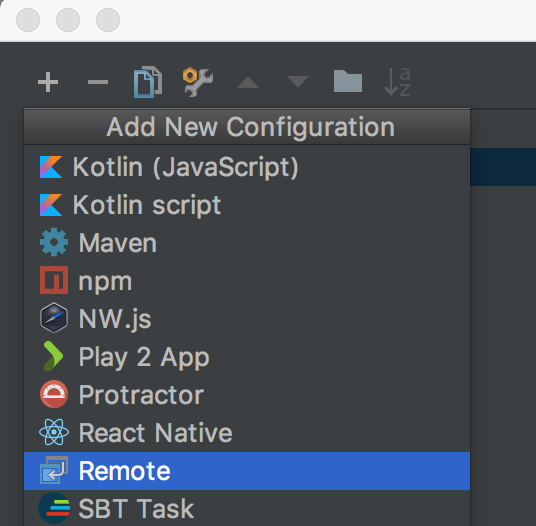 配置名称大家随意,我这里为Spark,远程调试的端口为5005,如果本地的5005端口被占用,改为其他端口即可。 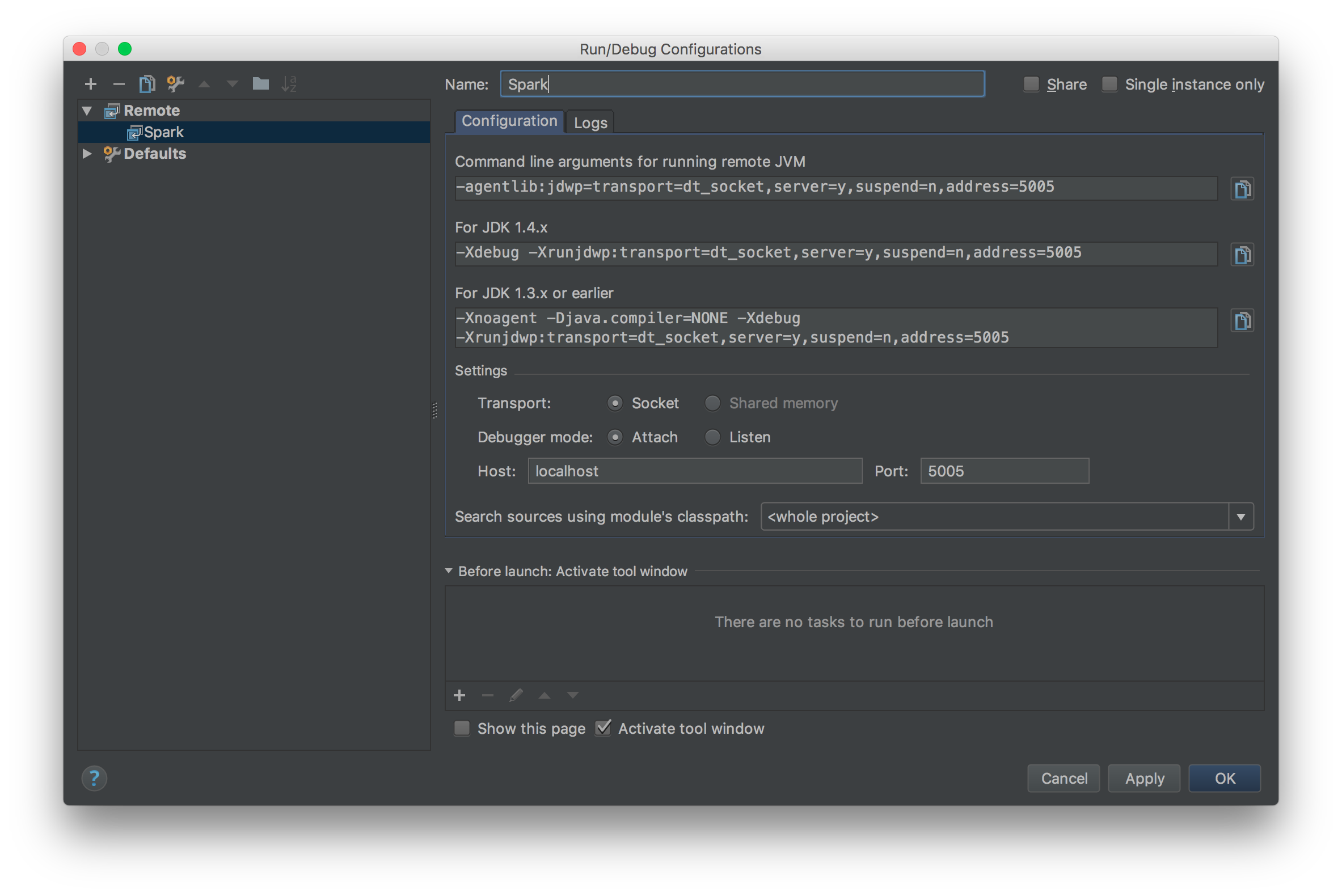 然后回到Terminal重新启动sbt,启动时需要添加远程调试参数:`build/sbt -jvm-debug 5005`,启动过程中会提示`Listening for transport dt_socket at address: 5005`,启动sbt后,我们就可以通过IDEA对sbt进行调试了。  接下来我们给SimpleSuite的test方法内部随意添加一个断点,回到sbt执行: ``` > project sql > set fork in Test := false > testOnly *SimpleSuite ``` 一切顺利的话,执行testOnly的过程中,我们的断点会被命中: 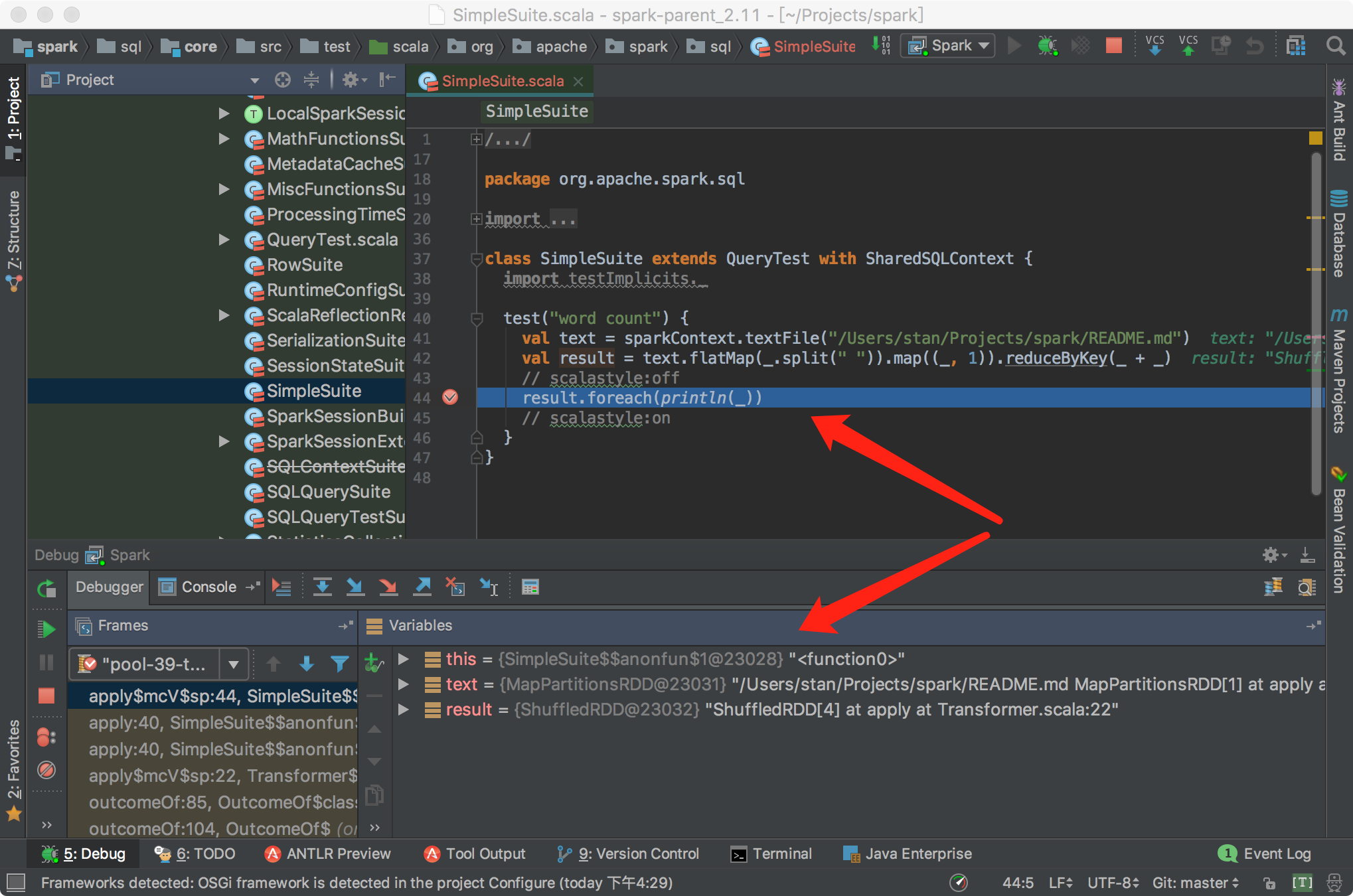 如果对Spark源码或SimpleSuite的代码做了修改只需要重新执行`testOnly *SimpleSuite`即可。 让IDEA命中断点有一个关键的语句:`set fork in Test := false`,这个语句的作用是让sbt执行Test时避免fork子进程。我们启动sbt的时候添加的远程调试端口是加在sbt上的,如果执行Test不在一个进程内,IDEA就无法命中断点。 如果频繁修改代码,反复执行`testOnly`难免有些不便,我们可以采用sbt的持续编译功能简化流程。执行时加上`~`,也就是`~testOnly *SimpleSuite`,这样,我们修改代码,在保存,sbt会监控文件变化并自动执行测试,超级方便。这种方式同样适用于compile,test,run等命令。 ## 总结 几个关键点: ``` # Spark源码目录下执行(以SimpleSuite为例): $ build/sbt -jvm-debug 5005 > project sql > set fork in Test := false > testOnly *SimpleSuite ``` OK,掌握以上技巧,我们就可以愉快的深入Spark源码内部,了解Spark的运作机制了。 非特殊说明,均为原创,原创文章,未经允许谢绝转载。 原始链接:sbt结合IDEA对Spark进行断点调试开发 赏 Prev Apache Spark 2.2.0 正式发布 Next 如何优雅地合并Spark官方Patch(PR)

